
ПІДТРИМАЙ УКРАЇНУ
ПІДТРИМАТИ АРМІЮ
What Are ORMs & Should You Use Them
ORM libraries typically must take care of multiple things behind the scenes. They include but are not...
ORM libraries typically must take care of multiple things behind the scenes. They include but are not limited to:
- Representing the domain model in the application
- Parsing the SQL query results from raw objects into the domain objects
- Generating SQL statements for querying and modifying the data
- Managing transactions and isolation levels
- Migrations
Let’s cover these one by one and see what can go wrong.
Domain model in the application
Domain models in the Object Oriented Application can be either stateful or stateless.
Stateful objects typically have some behavior. They modify their state via domain methods that do business processing.
Stateless objects are just bags of data. They are created in a transaction script. Objects do not change their state on their own but are rather handled in units of work and transactions.
Mapping from domain objects to the ORM logic is typically done via annotations or attributes. Each field is decorated with attributes describing how it should be handled on the database side - what column type to use, how to configure keys, relationships between tables, etc. We may put these annotations on the domain objects directly, or we may decide to have an in-between model for entities only. The latter also allows us to separate the model from the persistence infrastructure and is thus highly recommended.
However, domain models cannot be mapped to the entity model easily. This is called an Object-relational impedance mismatch . We may face issues like:
- Incompatible columns - we may not be able to represent database types in the OOP world and vice versa. For instance, text data may have different encoding, collation (order of characters in the alphabet), or comparison rules (whether lowercase and uppercase letters are to be considered the same or different)
- 1 to 1 and 1 to many relationships - they are always tricky when it comes to lazy loading and eager loading
- Inheritance - there are multiple ways to represent the inheritance hierarchy (table per class, table per concrete class, table per hierarchy). Performance may heavily depend on the way we structure our data in the database because of the joins and filtering we need to perform
One typical issue is n+1 queries. Let’s take the following schema:
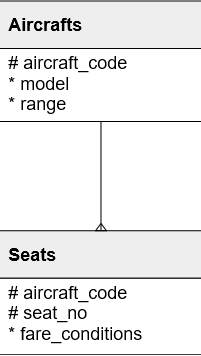
We have a table called Aircrafts. Each aircraft may have multiple Seats. We would like to get seats for every aircraft with the following code:
aircrafts = aircrafts.load();
for(aircraft in aircrafts) {
seatsCount = aircraft.seats.size;
}
This may generate the following queries:
SELECT * FROM aircrafts;
SELECT * FROM seats WHERE aircraft_code = 1;
SELECT * FROM seats WHERE aircraft_code = 2;
SELECT * FROM seats WHERE aircraft_code = 3;
...
SELECT * FROM seats WHERE aircraft_code = n;
We get one query to get all the aircraft, and then additional n queries to get the seats. This could be reduced to one query, though:
SELECT * FROM aircrafts
LEFT JOIN seats ON seats.aircraft_code = aircrafts.aircraft_code;
To get this faster query, we need to configure the ORM library to work in eager mode. This may not be a good idea to do it globally, and can’t be done blindly.
Parsing the results into the domain objects
Parsing the results by the ORM library is not as trivial as it may seem. This may especially be a problem when dealing with nested collections and related entities. Imagine that our entities have multiple unrelated details. For instance, the user entity may have details, questions, peers, etc. Let’s take the following code:
const user = repository.get("user")
.where("user.id = 123")
.leftJoin("user.details", "user_details_table")
.leftJoin("user.pages", "pages_table")
.leftJoin("user.texts", "texts_table")
.leftJoin("user.questions", "questions_table")
.leftJoin("user.reports", "reports_table")
.leftJoin("user.location", "location_table")
.leftJoin("user.peers", "peers_table")
.getOne();
This may generate the following query:
SELECT *
FROM users AS user
LEFT JOIN user_details_table AS detail ON detail.user_id = user.id
LEFT JOIN pages_table AS page ON page.user_id = user.id
LEFT JOIN texts_table AS text ON text.user_id = user.id
LEFT JOIN questions_table AS question ON question.user_id = user.id
LEFT JOIN reports_table AS report ON report.user_id = user.id
LEFT JOIN location_table AS location on location.user_id = user.id
LEFT peers_table AS peer ON peer.user_id = user.idWHERE user.id = '123'
This query may easily run for 30 seconds and return 300 thousand rows that are later flattened into one aggregation root by the ORM. However, if we split this into multiple queries like this:
const userQuery = repository.get("user").where("user.id = 123");
const user = userQuery().getOne();
const details = userQuery()
.leftJoin("user.details", "user_details_table")
.getOne();
const pages = userQuery()
.leftJoin("user.pages", "pages_table")
.get();
const texts = userQuery()
.leftJoin("user.texts", "texts_table")
.get();
const questions = userQuery()
.leftJoin("user.questions", "question_tables")
.get();
const reports = userQuery()
.leftJoin("user.reports", "reports_table")
.get();
const location = userQuery()
.leftJoin("user.location", "location_table")
.getOne();
const peers = userQuery()
.leftJoin("user.peers", "peers_table")
.get();
return {
...user,
...details,
...pages,
...texts,
...questions,
...reports,
...location,
...peers,
};
This will generate the following SQL queries:
SELECT *
FROM users AS user
WHERE user.id = '123';
SELECT *
FROM users AS user
LEFT JOIN user_details_table AS detail ON detail.user_id = user.id
WHERE user.id = '123';
SELECT *
FROM users AS user
LEFT JOIN pages_table AS page ON page.user_id = user.id
WHERE user.id = '123';
SELECT *
FROM users AS user
LEFT JOIN texts_table AS text ON text.user_id = user.id
WHERE user.id = '123';
SELECT *
FROM users AS user
LEFT JOIN questions_table AS question ON question.user_id = user.id
WHERE user.id = '123';
SELECT *
FROM users AS user
LEFT JOIN reports_table AS report ON report.user_id = user.id
WHERE user.id = '123';
SELECT *
FROM users AS user
LEFT JOIN locations_table AS location ON location.user_id = user.id
WHERE user.id = '123';
SELECT *
FROM users AS user
LEFT JOIN peers_table AS peer ON peer.user_id = user.id
WHERE user.id = '123';
While this generates many more queries, they are ultimately faster and can finish in one millisecond.
We can see that splitting one query into multiple may be very beneficial to the performance.
Generating SQL statements for querying and modifying the data
Generating an efficient query may be challenging. One example is the use of Common Table Expressions (CTEs). We have the boarding_passes table with nearly 8 million rows. Let’s say, that we run the following query:
WITH cte_performance AS (
SELECT *, MD5(MD5(ticket_no)) AS double_hash
FROM boarding_passes
)
SELECT COUNT(*)
FROM cte_performance AS C1
JOIN CTE_performance AS C2 ON C2.ticket_no = C1.ticket_no AND C2.flight_id = C1.flight_id AND C2.boarding_no = C1.boarding_no
JOIN CTE_performance AS C3 ON C3.ticket_no = C1.ticket_no AND C3.flight_id = C1.flight_id AND C3.boarding_no = C1.boarding_no
WHERE
C1.double_hash = '525ac610982920ef37b34aa56a45cd06'
AND C2.double_hash = '525ac610982920ef37b34aa56a45cd06'
AND C3.double_hash = '525ac610982920ef37b34aa56a45cd06'
It takes 13 seconds to execute. However, if we don’t use the CTE and encode the hashing directly, as in:
SELECT COUNT(*)
FROM boarding_passes AS C1
JOIN boarding_passes AS C2 ON C2.ticket_no = C1.ticket_no AND C2.flight_id = C1.flight_id AND C2.boarding_no = C1.boarding_no
JOIN boarding_passes AS C3 ON C3.ticket_no = C1.ticket_no AND C3.flight_id = C1.flight_id AND C3.boarding_no = C1.boarding_no
WHERE
MD5(MD5(C1.ticket_no)) = '525ac610982920ef37b34aa56a45cd06'
AND MD5(MD5(C2.ticket_no)) = '525ac610982920ef37b34aa56a45cd06'
AND MD5(MD5(C3.ticket_no)) = '525ac610982920ef37b34aa56a45cd06'
This query takes 8 seconds to complete. This is a nearly 40% improvement in the execution time.
However, some ORM operations can’t be translated into a single SQL query that easily. Let’s take Sequelize's findOrInsert . It first sends a SELECT query like this:
SELECT columns
FROM table AS T
WHERE T.id = '123'
LIMIT 1;
When this returns no rows, then the following function is created and executed:
CREATE
OR REPLACE FUNCTION pg_temp.testfunc (
OUT response person,
OUT sequelize_caught_exception text
) RETURNS RECORD AS $func_169876f086224f2e974c1775215fef4d$ BEGIN INSERT INTO table(id) VALUES (DEFAULT) RETURNING * INTO response; EXCEPTION WHEN unique_violation THEN GET STACKED DIAGNOSTICS sequelize_caught_exception = PG_EXCEPTION_DETAIL; END $func_169876f086224f2e974c1775215fef4d$ LANGUAGE plpgsql;
SELECT
(testfunc.response).id,
testfunc.sequelize_caught_exception
FROM
pg_temp.testfunc ();
DROP FUNCTION IF EXISTS pg_temp.testfunc ();
What’s more, this may still fail because of race conditions.
Other operations may result in even more sophisticated queries. Generally, using simpler functions is recommended to avoid the complexity.
Managing transactions and isolation levels
ORM must handle transactions. It needs to begin and terminate them when the time comes.
However, transactions may have isolation levels that can change the result of our queries and affect the performance. MySQL uses REPEATABLE READ by default, PostgreSQL goes with READ COMMITTED , DB2 uses Cursor Stability . Most ORMs use the database default isolation level, so this depends on the database we use. This means that our code may behave differently when a different database is used.
However, ORM can reconfigure that and use different settings. This can be buried down in some configuration that we’re not very aware of. This may also change between ORM versions. Some libraries don’t use transactions at all. And keep in mind that we may get duplicates when using READ COMMITTED .
The rule of thumb is to manually set the isolation level and keep it consistent. Do not rely on defaults, do not leave this unattended.
Migrations
Migrations must be understood by the ORM. Either we control migrations directly in the ORM (and the ORM makes the changes in the database), or we just modify the domain in the ORM and the library figures out how to handle that. If we have multiple applications with incompatible technical stacks, then managing migrations may be harder.
Some libraries store the list of migrations executed against the database. They typically create a new table with the history of migrations. This works great with one application only and may break when multiple applications are in place.
Some other libraries assume our migrations are idempotent, so they can be executed many times. This makes managing the migrations much easier (we can always rerun them and nothing breaks), but writing such migrations is more challenging.
How to manage transactions efficiently? Some ideas to may consider:
- Keeping migrations separately from the ORM - to allow for multiple heterogeneous applications running against the same database
- Keeping migrations in plain SQL files makes it easy to analyze them and use them with different tools
- Migrations should be numbered in a consistent way to be executed in an order
- Implementing migrations as idempotent operations. This simplifies the management
Summary
ORM libraries simplify multiple things. However, they also introduce additional layers of complexity that may result in performance drops and issues on their own. Developers need to understand the consequences of integrating these libraries into their codebase. Metis can help a lot with observability and troubleshooting.
Ресурс : dev.to

