ПІДТРИМАЙ УКРАЇНУ
ПІДТРИМАТИ АРМІЮ
Use dbt and Duckdb instead of Spark in data pipelines
At Data Minded, we have observed a growing popularity of dbt among our clients in recent years. While it has primarily been used for data transformations on top of a data warehouse (DWH), we also see the potential for using dbt together with Duckdb as an
Why dbt trumps Spark in data pipelines?
For more than a decade, Apache Spark has been the go-to option for carrying out data transformations. However, with the increasing popularity of cloud data warehouses in the past five years, dbt has rapidly gained traction. In fact, Kris, the CEO of Data Minded, wrote a blog about dbt and Spark over 2 years ago. It was titled “Why dbt Will One Day Be Bigger Than Spark”. In my opinion, the key advantages of dbt over Spark are:
Broader target audience
In order to use dbt, you mainly need to know SQL. Since SQL has been around for over 40 years, many people have used SQL before and can thus understand/write/maintain dbt code. Also, you are not limited to only data engineers, as is often the case for Spark, but also Data scientists, Data analysts, and BI developers would feel comfortable in maintaining a dbt project.
Simple execution
While I like Spark for orchestrating my data transformations, I must admit that it can be a complex beast with many configuration options and pitfalls. I have noticed this over and over again when onboarding new data engineers in my team. They start from a working pipeline, make a small change in the ordering of a join or change a configuration setting (e.g. spark.sql.shuffle.partitions, spark.sql.autoBroadcastJoinThreshold) and all of a sudden the pipeline fails. Most of the time this is because they do not understand (yet) how Spark distributes computations.
Dbt greatly reduces this complexity for the data engineer as it offloads the computational burden towards the DWH (e.g. Snowflake, Redshift). This means that most users do not need to understand the low-level execution of queries in the DWH except when they want to optimize the performance of a specific query. A downside of pushing all your computation to your DWH is that the cloud data warehouses typically charge more for processing data than other execution engines.
Most companies don’t have big data
The great thing about Spark is that it enables you to process terabytes of data. It does this by distributing the computation across multiple nodes, but this coordination/communication aspect can introduce significant overhead when working with medium-sized datasets (10–100 Gb). Over the past 5 years of working as a data engineer, I noticed that 90% of my data pipelines only processed medium-sized datasets.
Additionally, the rise of cloud computing made virtual machines with 256 Gb of RAM even more readily available, which opens up the question:
Do we need a complex distributed system like Spark for handling our data processing if our datasets fit on just a single machine?
Over the past couple of years, many new technologies have emerged that try to fill this gap (e.g. polars, pyarrow ecosystem,…). They simplify the execution by running on a single node but still require you to write Python code. This limits the number of people that can maintain it, as we all know that data engineers are a scarce resource. So I was wondering, can we do better?
Dbt and Duckdb to the rescue
Initially, I had reservations about using dbt for my data pipelines since it required storing all my data in a DWH. While this isn’t much of an issue for structured data, it is not well-suited for semi-structured data. In the past year, DuckDB, which is an in-process OLAP database, has gotten quite some attention. It can be seen as a single-node equivalent of a cloud data warehouse.
My excitement grew when I discovered the dbt-duckdb adapter, which is being developed by Josh Wills, and I finally understood what the fuzz was all about. Combining duckdb with dbt results in the following 3 benefits:
No need to rely on your DWH for all processing
Cloud data warehouses are impressive but can also become very expensive if you want to use them for all your data transformations. Duckdb runs standalone without external dependencies, so you can easily embed it in any Python or Java program. This makes it an ideal candidate in many situations, from local testing to processing dbt queries in your pipeline.
Integrate seamlessly with external storage
Duckdb supports writing data to an external system and storing data in its own database format. It also natively supports common file formats (e.g. CSV, Parquet).
The external storage feature of Duckdb makes it possible to seamlessly migrate a data pipeline written in Spark to a data pipeline using dbt with Duckdb. This means you can rewrite the processing while keeping the in- and output of your job the same (e.g. parquet files on blob storage).
No need to change your data platform
In many of my previous projects, I encountered a data platform with similar building blocks for implementing data pipelines:
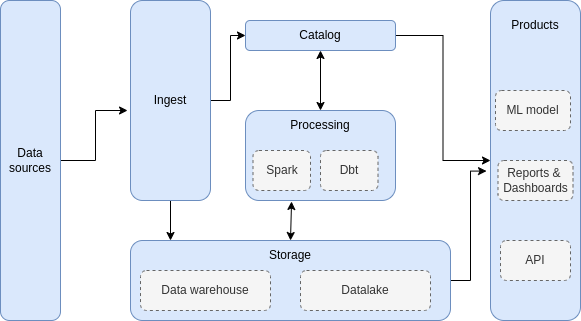
High-level components in a data platform for batch data processing.
Data is ingested and transformed using commodity hardware, and afterward, the results are stored in a data lake. If there is a specific need to have the data in a DWH, you can push the results to the DWH instead of the data lake (e.g. allow querying in Tableau or PowerBi,…).
With dbt and Duckdb you now have an alternative for using Spark as your processing engine in the following scenarios:
Dbt with Duckdb is faster than Spark
The last aspect that I wanted to investigate, is whether it is cheaper to use DBT with Duckdb compared to Spark for performing data transformations on medium-sized datasets. In order to compare both, I used the TPC-DS benchmark, which is an industry-standard for comparing database performance.
Test setup
Results
In the results, I compare the Dbt + Duckdb performance with 3 different Spark setups:
I show the query duration (*) for only a few queries in the TPC-DS benchmark. I chose queries 40, 70, 81, 81, and 64 because they have very distinct query patterns; more details about this can be found in The Making of TPC-DS.
2 things stand out based on the results:
(*) I do not take into account the time it takes to spin up Kubernetes pods/nodes and instead, only look at the time it takes to execute the query. Running a Spark pipeline end-to-end with 2 executors will probably have even worse performance compared to dbt as we need to create multiple pods (Submitter pod, driver pod, 1–2 executor pods).
(**) Query 64 is the heaviest query in the benchmark as it joins 2 of the largest fact tables together. Even though Duckdb flushes data to disk when it cannot allocate any more memory, I could not successfully execute the query due to being out of memory. The same thing happened when trying with larger instances. I will need to investigate in more detail why this is the case.
Conclusion
In this blog post, I started with the advantages that dbt offers over Spark, such as a larger SQL-savvy audience and simpler execution. These benefits, combined with the fact that most companies don’t handle big data, raise questions about whether Spark is the best tool for them.
As an alternative, I showed that dbt in combination with Duckdb is great when your datasets are not too big, and your workloads are SQL compatible.
Finally, I proved the value of dbt and Duckdb by running the TPC-DS benchmark. The results show that dbt with DuckDB outperforms Spark on all queries except one.
Ресурс : medium.com