ПІДТРИМАЙ УКРАЇНУ
ПІДТРИМАТИ АРМІЮ
Стратегії доставки та дедуплікації повідомлень
Працюючи з розподіленими системами ви, швидше за все, насамперед ознайомитеся з різними патернами взаємодії. Більшість програмістів чудово обізнані про існуючі варіанти.
Працюючи з розподіленими системами ви, швидше за все, насамперед ознайомитеся з різними патернами взаємодії. Більшість програмістів чудово обізнані про існуючі варіанти:
- at-most-once (максимум один раз)
- at-least-once (мінімум один раз)
- та exactly-once delivery (суворо одноразова доставка).
Вони добре описані, тому коротко нагадаємо, що при доставці at-most-once повідомлення може бути втрачено. Під час доставки at-least-once всі повідомлення будуть доставлені один або кілька разів. А exactly-once доставки не існує. Втім, це не зовсім так. З точки зору доставки повідомлень "exactly-once" неможлива, але при використанні таких методів, як дедуплікація, ми можемо досягти "effectively-once" (ефективно один раз), що є набагато більш відповідною назвою. Результат або ефект може бути досягнутий один раз, і це можливо.
Доставка at-most-once
Семантика доставки at-most-once дуже проста. Мені подобається називати це YOLO-доставкою (You Only Live Once – живемо лише один раз). Ми можемо надіслати повідомлення із системи A до B, і нас не хвилює, отримає його B чи ні. Це дуже корисно для деяких випадків масового отримання даних, наприклад, для збирання кліків на веб-сторінках, під час відстеження автомобіля тощо.
Якщо ви іноді втрачаєте повідомлення, це або взагалі не проблема, або після того, що сталося, можна дуже легко привести стан у норму.
Доставка at-least-once
У цьому випадку нам потрібно бути впевненими, що повідомлення було доставлене. Допустимо, це запит на грошовий переказ або оплата покупок у кошику. Такі повідомлення не можуть бути втрачені, оскільки це виллється у значні нестиковки стану, не кажучи вже про те, що буде зруйновано репутацію компанії, яка в наш час є дуже важливою для підтримки будь-якого бізнесу.
У більшості ситуацій продюсер (A) відповідає за at-least-once доставку хоча б одного повідомлення (m1), очікуючи на підтвердження від консьюмера (B) про те, що повідомлення (m1) було доставлено. Якщо його не отримано, продюсер надсилає повідомлення знову.
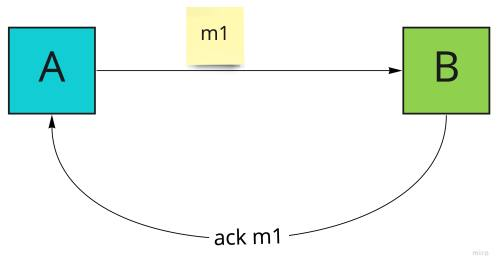
Це стандартний підхід, і здебільшого це цілком прийнятний вибір. Якщо вам потрібно більше подробиць про можливу реалізацію, перегляньте цей блог про патерн Transaction Outbox Pattern.
Багато розробників забувають, що ми можемо розгорнути цю залежність і зробити консьюмера (B) відповідальним за гарантію доставки "at-least-once". Припустимо, що продюсер (A) надсилає повідомлення m1, m2, m3 і з якихось причин повідомлення m4 втрачається. Наступним повідомленням від продюсера буде m5.
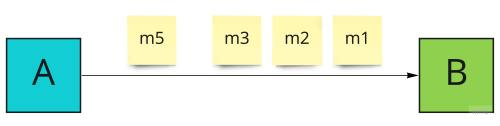
Консьюмер не повинен нічого підтверджувати, але повинен стежити за порядковим номером повідомлення. У разі виявлення пропущеного повідомлення він запускає стратегію повторної доставки. Найпростішим варіантом буде попросити продюсера надіслати всі повідомлення ще раз, починаючи з пропущеного офсету.
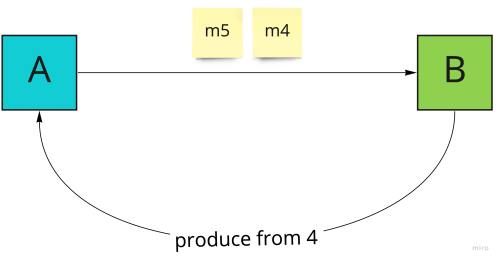
Ця стратегія особливо зручна, коли необхідно забезпечити порядок обробки за консьюмера. Інакше ми могли б асинхронно запросити у продюсера лише офсети, що бракують, і продовжити обробку. В обох випадках значення офсету дуже важливе.
Якщо ви можете генерувати для кожного повідомлення строго монотонно зростаючий порядковий номер без пробілів, то реалізація доставки за принципом "at-least-once" буде досить простою. Іноді це глобальна послідовність, але часто вона генерується для кожного агрегату домену, який є зберігачем цілісності стану.
Майте на увазі, що якщо ми допускаємо перепустки в послідовності з боку продюсера, як у випадку з багатовузловою установкою, необхідно враховувати це і на стороні консьюмера. У цьому випадку логіка повторної доставки буде складнішою.
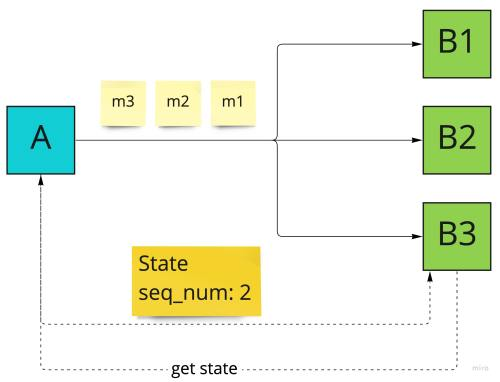
Іноді потік повідомлень може бути "перезапущено". Як приклад цього може бути комунікація fun-out:
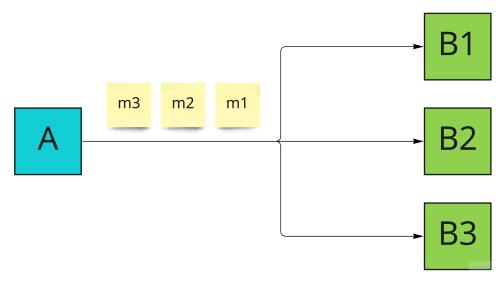
Як консьюмери можуть виступати мобільні пристрої, які обробляють потік змін стану. Це може бути WebSocket з оновленнями стану реєстраційного журналу обміну повідомлень або оновлення стану розмови для вирішення, подібного до Whatsapp. Один мобільний пристрій може на мить втратити зв'язок і пропустити деякі повідомлення WebSocket.
У цьому випадку буде потрібно реконсиляція стану:
- буферизація основного потоку повідомлень,
- запит актуального стану з поточним порядковим номером
- використання стану та початок обробки потоку повідомлень з цього порядкового номера (повідомлення m1 має бути проігноровано)
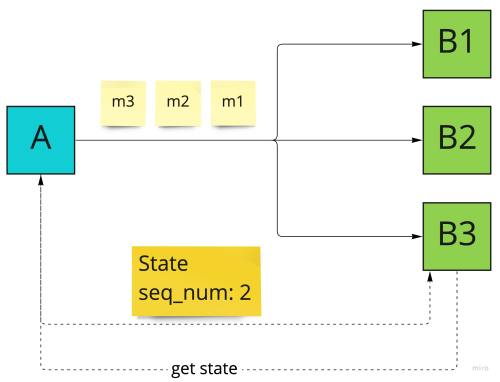
Схоже, що доставка at-least-once консьюмера потребує більше зусиль. Так і є, але в деяких випадках це варте того, щоб заплатити певну ціну.
В основному така стратегія доставки за принципом "at-least-once" не вимагає великих витрат трафіку. Реконсиляція траплятиметься відносно рідко, тому нам не доведеться переплачувати за підтвердження кожного повідомлення. Я знаходжу це особливо корисним, коли експериментую з WebSocket-комунікаціями для багатьох клієнтів, які споживають один і той самий потік даних.
Доставка "effectively-once" з дедуплікацією
Як щодо знаменитої та такої затребуваної доставки точно/ефективно один раз (exactly/effectively-once)? Звісно, ми всі знаємо, як вирішити цю проблему. Кожне повідомлення повинно мати певний унікальний ідентифікатор, за допомогою якого можна перевірити, чи було його використано раніше. Тут є дві готчі (gotchas).
По-перше, наша дія має бути збережена в одній транзакції з унікальним ідентифікатором. У псевдокоді це може виглядати так:
begin transaction;
update something based on a given message;
save unique id from the message if not present;
end transactionДля класичної RDBMS домогтися цього не важко. Окрема таблиця з унікальним обмеженням на стовпець id, і можна розпочинати роботу. У разі обробки того самого повідомлення двічі, транзакція завершиться невдало, можна припустити, що це повідомлення вже оброблялося раніше.
Єдина проблема полягає в тому, що таку дедуплікацію не так просто реалізувати для інших рішень щодо зберігання даних.
У Redis транзакції мають дещо іншу семантику, оскільки це сховище ключів, і для імітації такої поведінки слід використовувати оператор WATCH.
У розподілених базах даних, таких як Cassandra є певна підтримка транзакцій, але з нею слід бути дуже обережним. Будь-яке оновлення або вставка з оператором IF запускає під капотом легку транзакцію. Сама назва оманлива, бо це досить важка операція:
Lightweight transactions should not be used casually as the latency of operations increases fourfold due to the round-trips necessary between the CAS coordinators.Легкові транзакції не слід використовувати без особливої потреби, оскільки затримка операцій збільшується в чотириразовому розмірі через необхідні цикли обробки між CAS-координаторами.
Також у Cassandra (як і в багатьох розподілених базах даних) ви не оновите дві таблиці в одній транзакції просто тому, що вони можуть бути на двох різних вузлах.
Порада: переконайтеся, що базове сховище підтримує транзакції, як зазначено вище, перш ніж ви пообіцяєте забезпечити ефективну одноразову (effectively-once) обробку.
Друга проблема полягає в тому, що ми не можемо зберігати унікальні ідентифікатори вічно. Або ми стикаємося з труднощами у продуктивності за дуже великого унікального індексу, або досягаємо обмеження щодо обсягу зберігання даних, які не мають відношення до бізнесу. Тому залежно від вимог зберігати унікальні ідентифікатори доведеться за останню годину, тиждень, місяць чи рік.
Складіть план видалення старих ідентифікаторів автоматично або вручну, але переконайтеся, що кожному зрозумілі наслідки тієї чи іншої стратегії дедуплікації. Це особливо важливо у разі перебоїв у роботі, коли наша система відключається на кілька хвилин/годин і, відновившись, намагається знову опрацювати деякі повідомлення.
Якщо на стороні консьюмера узгоджено доставку за принципом "at-least-once", ми можемо використовувати порядковий номер для дедуплікації. Виходячи з того, що чергове повідомлення матиме порядковий номер + 1, потрібно зберігати тільки поточне значення послідовності. Такий вид дедуплікації не матиме обмежень у часі/сховищі.
Однак, як я вже згадував, складність полягає в тому, щоб згенерувати порядковий номер та уникнути прогалин. Іноді може виникнути спокуса використовувати існуючі технічні поля, наприклад, офсет повідомлення від Kafka-брокера. На жаль, це не буде надійною дедуплікацією, бо ми можемо створювати дублікати на боці продюсера.
Включення ідемпотентності мінімізує можливість появи дублікатів, але не усуне її повністю.
Автор оригіналу: Andrzej Ludwikowski

