
ПІДТРИМАЙ УКРАЇНУ
ПІДТРИМАТИ АРМІЮ
Processing a billion rows in PHP: how to do it efficiently?
Learn how to optimize big data in PHP. Strategies, tools, and examples.
You may have heard of the "The One Billion Row Challenge" (1brc) and in case you don't, go checkout Gunnar Morlings's 1brc repo .
I got sucked in because two of my colleagues have entered the competition and are on the leaderboard .
PHP is not known for its speed, but as I am working on the PHP profiler I thought I give it a shot and see how fast it can get.
A first naive approach
I cloned the repository and created the billion row dataset in measurements.txt . After that I started building my first naive implementation of something that could solve the challenge:
$stations[$data[0]][1]) {
$stations[$data[0]][1] = $data[1];
}
}
}
ksort($stations);
echo '{';
foreach($stations as $k=>&$station) {
$station[2] = $station[2]/$station[3];
echo $k, '=', $station[0], '/', $station[2], '/', $station[1], ', ';
}
echo '}';
There is nothing wild in here, just open the file, use fgetcsv() to read the data. If the station is not found already, create it, otherwise increment the counter, sum the temperature and see if the current temperature is lower than or higher than min or max and updated accordingly.
Once I have everything together, I use ksort() to bring the $stations array in order and then echo out the list and calculate the average temperature while doing so (sum / count).
Running this simple code on my laptop takes25 Minutes????
Time to optimise and have a look at the profiler:
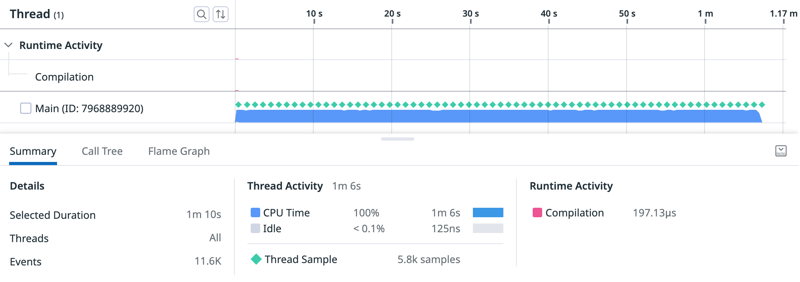
The timeline visualisation helps me see, that this is clearly CPU bound, file compilation at the beginning of the script is negligible and there are no garbage collection events.
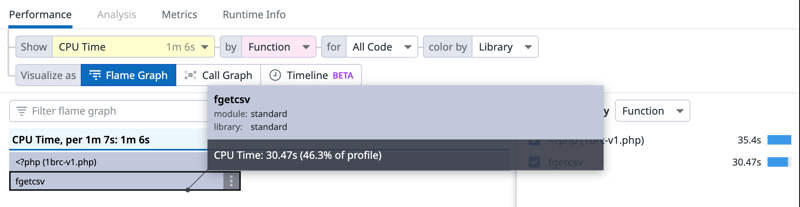
The flame graph view is helpful as well in showing that I am spending 46% of CPU time in fgetcsv() .
fgets() instead of fgetcsv()
The first optimisation was to use fgets() to get a line and split on the ; character manually instead of relying on fgetcsv() . This is because fgetcsv() does a whole lot more than what I need.
// ...
while ($data = fgets($fp, 999)) {
$pos = strpos($data, ';');
$city = substr($data, 0, $pos);
$temp = substr($data, $pos+1, -1);
// ...
Additionally I refactored $data[0] to $city and $data[1] to $temp everywhere.
Running the script again with just this one change already brought the runtime down to19m 49s. In absolute numbers, this is still a lot but also: it's21% down!
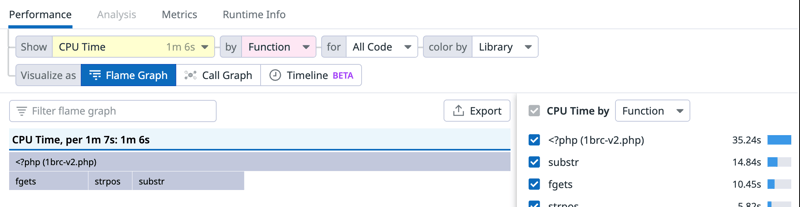
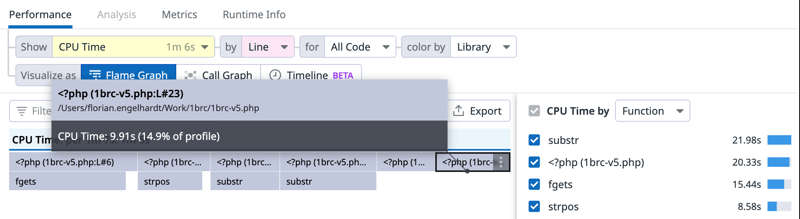
The flame graph reflects the change, switching to showing the CPU time by line also reveals what is going on in the root frame:
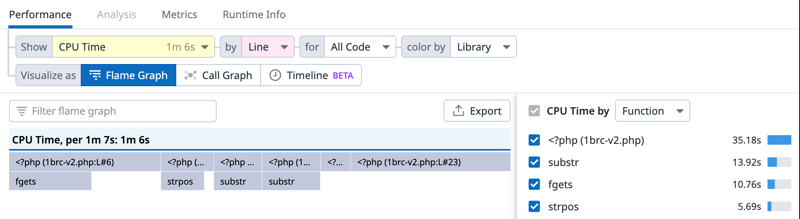
I am spending ~38% CPU time in lines 18 and 23, which are:
18 | $stations[$city][3] ++;
| // ...
23 | if ($temp > $stations[$city][1]) {
Line 18 is the first access to the $stations array in the loop, otherwise it is only an increment and line 23 is a comparison, nothing that seems expensive at first glance, but lets do few more optimisations and you'll see what is taking time here.
Using a reference where possible
$station = &$stations[$city];
$station[3] ++;
$station[2] += $temp;
// instead of
$stations[$city][3] ++;
$stations[$city][2] += $data[1];
This should help PHP to not search for the key in the $stations array on every array access, see it like a cache for accessing the "current" station in the array.
And it actually helps, running this only takes17m 48s, another10% down!
Only one comparison
While looking at the code, I stumbled over this piece:
if ($temp $station[1]) {
$station[1] = $temp;
}
In case the temperature is lower than min, it cannot be higher than max anymore, so I made this an elseif and maybe spare some CPU cycles.
BTW: I don't know anything about the order of temperatures in measurements.txt , but depending on that order it could make a difference if I first checked the one or the other.
The new versions takes 17m 30s, which is another ~2%. Better than just jitter, but not by a lot.
Adding type casts
PHP is known as a dynamic language and it is something that I valued a lot when I just got started writing software, one less problem to care about. But on the other side, knowing the types helps the engine make better decisions when running your code.
$temp = (float)substr($data, $pos+1, -1);
Guess what? This simple cast makes the script run in just13m 32swhich is a whoppingperformance increase of 21%!
18 | $station = &$stations[$city];
| // ...
23 | } elseif ($temp > $station[1]) {
Line 18 still shows up with 11% of CPU time spend, which is the access to the array (finding the key in the hash map, which is the underling data structure used for associative arrays in PHP).
Line 23's CPU time dropped from ~32% to ~15%. This is due to PHP not doing type juggling anymore. Before the type cast, $temp / $station[0] / $station[1] were strings , so PHP had to convert them to float in order to compare them on every single comparison.
What about JIT?
OPCache in PHP is by default disabled in CLI and needs the opcache.enable_cli setting to be set to on . JIT (as part of OPCache) is default enabled, but effectively disabled as the buffer size is set to 0 , so I set the opcache.jit-buffer-size to something, I just went with 10M . After these changes have been applied, I re-ran the script with JIT and see it finish in:
7m 19s????
which is45.9%less time spend!!
What more?
I already brought the runtime down from 25 minutes in the beginning to just ~7 minutes. One thing that I found absolutely astonishing is that fgets() allocates ~56 GiB/m of RAM for reading a 13 GB file. Something seems off, so I checked the implementation of fgets() and it looks like that I can spare a lot of these allocations by just omitting the len argument to fgets() :
while ($data = fgets($fp)) {
// instead of
while ($data = fgets($fp, 999)) {
Comparing the profile before and after the change gives this:
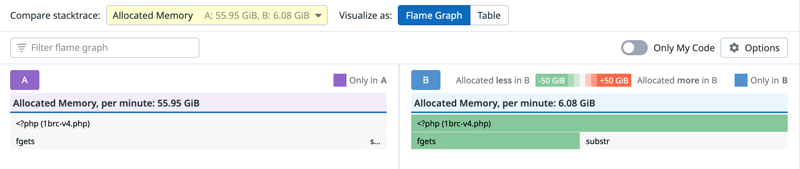
You might think that this gives a lot of performance improvement, but it is just ~1%. This is because those are small allocations which the ZendMM can handle in bins and those are blazingly fast.
Can we make it even faster?
Yes, we can! So far my approach was single threaded, which is the nature of most PHP software, but PHP does support threads in user land through the parallel extension .
Reading the data in PHP is a bottleneck as the profiler clearly shows. Switching from fgetcsv() to fgets() and manual split helps, but this is still taking a lot of time, so lets use threads to parallelise reading and processing the data and then afterwards combine the intermediate results from the worker threads.
*/
function get_file_chunks(string $file, int $cpu_count): array {
$size = filesize($file);
if ($cpu_count == 1) {
$chunk_size = $size;
} else {
$chunk_size = (int) ($size / $cpu_count);
}
$fp = fopen($file, 'rb');
$chunks = [];
$chunk_start = 0;
while ($chunk_start
*/
$process_chunk = function (string $file, int $chunk_start, int $chunk_end): array {
$stations = [];
$fp = fopen($file, 'rb');
fseek($fp, $chunk_start);
while ($data = fgets($fp)) {
$chunk_start += strlen($data);
if ($chunk_start > $chunk_end) {
break;
}
$pos2 = strpos($data, ';');
$city = substr($data, 0, $pos2);
$temp = (float)substr($data, $pos2+1, -1);
if (isset($stations[$city])) {
$station = &$stations[$city];
$station[3] ++;
$station[2] += $temp;
if ($temp $station[1]) {
$station[1] = $temp;
}
} else {
$stations[$city] = [
$temp,
$temp,
$temp,
1
];
}
}
return $stations;
};
$chunks = get_file_chunks($file, $threads_cnt);
$futures = [];
for ($i = 0; $i run(
$process_chunk,
[
$file,
$chunks[$i][0],
$chunks[$i][1]
]
);
}
$results = [];
for ($i = 0; $i value();
foreach ($chunk_result as $city => $measurement) {
if (isset($results[$city])) {
$result = &$results[$city];
$result[2] += $measurement[2];
$result[3] += $measurement[3];
if ($measurement[0] &$station) {
echo "\t", $k, '=', $station[0], '/', ($station[2]/$station[3]), '/', $station[1], ',', PHP_EOL;
}
echo '}', PHP_EOL;
This code does a few things, first I scan the file and split it into chunks that are \n aligned (for I am using fgets() later). When I have the chunks ready, I start $threads_cnt worker threads that then all open the same file and seek to their assigned chunk start and read and process the data till the chunk end, returning an intermediate result that afterwards gets combined, sorted and printed out in the main thread.
This multithreaded approach finishes in just:
1m 35s
Is this the end?
Nope, certainly not. There is at least two more things to this solution:
- I am running this code on MacOS on Apple Silicon hardware which is crashing when using the JIT in a ZTS build of PHP , so the 1m 35s result is without JIT, it might be even faster if I could use it
- I realised that I was running on a PHP version that was compiled using
CFLAGS="-g -O0 ..."due my needs in my day to day work ????
I should have checked this in the beginning, so I re-compiled PHP 8.3 using CLFAGS="-Os ..." and my final number (with 16 threads) is:
27.7 seconds
This number is by no means comparable to what you can see in the leaderboard of the original challenge and this is due to the fact that I ran this code on total different hardware.
This is a timeline view with 10 threads:
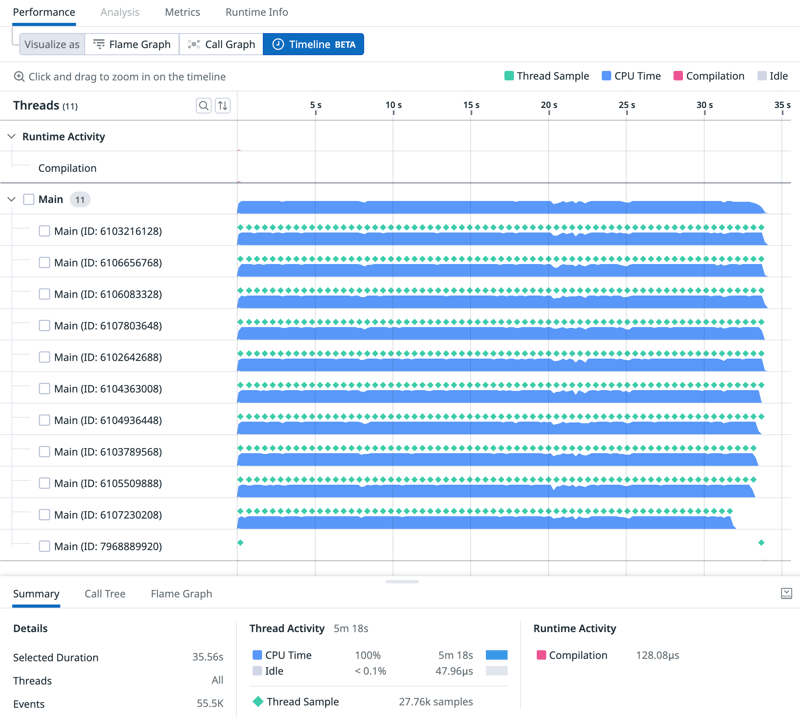
The thread at the bottom is the main thread, waiting for the results from the worker threads. Once those workers have returned their intermediate results the main thread can be seen working on combining and sorting everything. We can also clearly see, that the main thread is by no means the bottleneck. In case you want to try to optimise this even further, concentrate on the worker threads.
What did I learn on the way?
Each abstraction layer simply trades usability/integration for CPU cycles or memory. fgetcsv() is super easy to use and hides a lot of stuff, but this comes at a cost. Even fgets() hides some stuff from us but makes it super convenient to read the data.
Adding types to your code will help the language either optimise execution or will stop type juggling which is something you do not see but still pay for it with CPU cycles.
JIT is awesome, especially when dealing with CPU bound problems!
It is definitely not the nature of most PHP software, but thanks to parallelisation (using ext-parallel ) we could push the numbers down significantly.
The END
I hope you had as much fun reading this article as I had. In case you want to further optimise the code, feel free to grab this and leave a comment how far you got.
Ресурс : dev.to

