
ПІДТРИМАЙ УКРАЇНУ
ПІДТРИМАТИ АРМІЮ
How I built a Deep Learning Powered Search Engine
We use search engines everyday. Without them, we would be using the Internet in a much different way,...
We use search engines everyday. Without them, we would be using the Internet in a much different way, a way which I can't imagine what it would be like.
I decided to have a go at making my own small search engine, using Deep Learning to power the search results.
Breaking the problem down
Because making a fully fledged search engine is a very long and expensive task, I decided that my search engine would be for Wikipedia pages only (a.k.a given a search query, it will return any relevant Wikipedia pages for it)
There were 3 main steps to building this search engine:
- Find/Create a database of Wikipedia pages
- Index the database of pages
- Efficiently match search queries to pages in the index
Creating the Database
Instead of trying to find a database of Wikipedia pages online, I decided to create my own, simply because I wanted to build a web crawler!
What is a web crawler?
A web crawler is initially given a few starting URLs to visit. They then visit these URLs and parse through the HTML to find more URLs they can visit. Any URLs they find are added to a queue, so that they can visit them later.
Search engines, like Google and Bing, use web crawlers to keep adding to their index of website links, so that they can come up in their search results.
Since most of the URLs on Wikipedia pages are URLs to other Wikipedia pages, all I had to do was write a simple, generic web crawler and feed it a few intial Wikipedia pages.
import requests
import os
from tinydb import TinyDB
from html.parser import HTMLParser
db = TinyDB("results.json")
def get_host(url):
while os.path.dirname(url) not in ["http:", "https:"]:
url = os.path.dirname(url)
return url
class Parser(HTMLParser):
def __init__(self):
super(Parser, self).__init__(convert_charrefs=True)
self.url = ""
self.urls = []
self.meta_description = ""
self.title = ""
self.paragraph_content = ""
self.paragraph = False
self.set_description = False
self.set_title = False
def set_url(self, url):
if url[-1] == "/":
if os.path.dirname(url[:-1]) not in ["http:", "https:"]:
url = url[:-1]
self.url = url
def handle_starttag(self, tag, attrs):
if tag == "meta":
for attr in attrs:
if attr[0] == "name" and attr[1] == "description":
self.set_description = True
if self.set_description:
if attr[0] == "content":
self.meta_description = attr[1]
self.set_description = False
elif tag == "a":
for attr in attrs:
if attr[0] == "href":
link = attr[1]
if link:
if link[0] == "/":
link = get_host(self.url) + link
self.urls.append(link)
elif "http://" in link and link.index("http://") == 0:
self.urls.append(link)
elif "https://" in link and link.index("https://") == 0:
self.urls.append(link)
elif tag == "p" and len(self.paragraph_content) < 100:
self.paragraph = True
elif tag == "title":
self.set_title = True
def handle_endtag(self, tag):
if tag == "p":
self.paragraph = False
def handle_data(self, data):
if self.set_title:
self.title = data
self.set_title = False
elif self.paragraph:
self.paragraph_content += data
def clear(self):
self.urls = []
self.meta_description = ""
self.title = ""
self.paragraph_content = ""
self.paragraph = False
self.set_description = False
self.set_title = False
def crawl(start_queue):
parser = Parser()
queue = start_queue
seen_urls = []
while len(queue) > 0:
if queue[0] not in seen_urls:
try:
print (queue[0])
page = requests.get(queue[0])
parser.set_url(queue[0])
parser.feed(page.text)
db.insert({
"title": parser.title,
"description": parser.meta_description,
"content": parser.paragraph_content,
"url": queue[0]
})
seen_urls.append(queue[0])
queue = queue + parser.urls
parser.clear()
except:
pass
queue = queue[1:]
crawl(["https://en.wikipedia.org/wiki/Music", "https://en.wikipedia.org/wiki/Cricket", "https://en.wikipedia.org/wiki/Football"])
Everytime the crawler visits a page, it scans through the HTML for any a tags and adds its href attribute to the queue.
It also records the page's title, found in between the title tags, the first 100 characters of the page's article, by looking at the content within the p tags and the page's meta description (however after crawling, I found that none of the Wikipedia pages have meta descriptions!)
After the page is scanned through, its URL and recorded details are saved to a local JSON file, using TinyDB.
I ran the crawler for a few mintues and managed to scrape around 1000 pages.
Indexing the Database
To return relevant pages to a user's search query, I was planning to use aKNNalgorithm to compare the vector encodings of the search query and the vector encodings of the page contents store in the database.
Vector encodings of natural language are crucial when it comes to understanding what a user is saying. As you will see later, I decided to use a Transformer model to encode sentences into a vector representation.

With what I had so far, it was possible to build a working search engine with the above method in mind, but it would be extremely inefficient, since it would involve going through EVERY record in the database, vectorising their article's content and comparing it to the query vector.
Increasing Search Efficiency
In order to increase the efficiency of the search, I had an idea to index/preprocess the database, in order to reduce the search space for the KNN algorithm.
The first step was to vectorise the content of all the pages I had scraped and stored in my database.
from tinydb import TinyDB
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
model = SentenceTransformer('sentence-transformers/stsb-roberta-base-v2')
db = TinyDB("results.json")
contents = []
for record in db:
content = record["content"]
contents.append(content)
embeddings = model.encode(contents)
As you can see, for vectorising sentences, I used the SentenceTransformer library and the "stsb-roberta-base-v2" transformer model, which was fine-tuned for tasks like Neural Search, where a query needs to be matched with relevant documents (the exact task I had at hand).
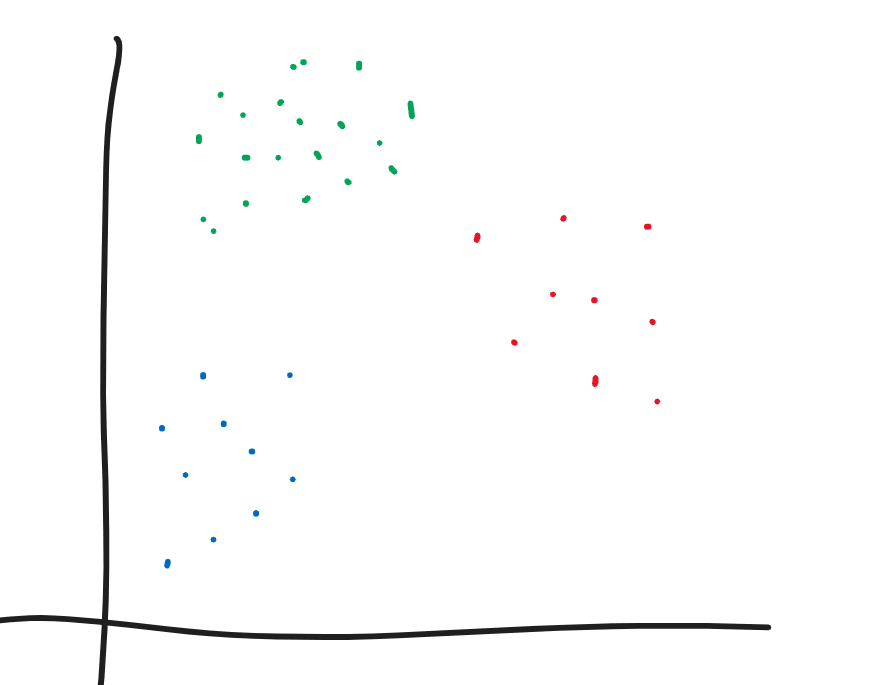
Now that I had all the vector representations of the pages, I decided to cluster semantically similar pages together, using the K-Means clustering algorithm.
The idea behind this was that, when a search query is entered, the query would be vectorised and be classified into a cluster. Then we could perform KNN with the pages in that cluster only, instead of the whole database, which should improve efficiency.
kmeans = KMeans(n_clusters=3)
kmeans.fit(embeddings)
buckets = {}
for record, label in zip(db, kmeans.labels_):
if label not in buckets:
buckets[label] = []
buckets[label].append(dict(record))
import pickle
pickle.dump(kmeans, open("kmeans-model.save", "wb"))
pickle.dump(buckets, open("buckets.save","wb"))
Clustering pages
from sentence_transformers import SentenceTransformer
import pickle
import numpy as np
from sklearn.neighbors import NearestNeighbors
model = SentenceTransformer('sentence-transformers/stsb-roberta-base-v2')
kmeans = pickle.load(open("cluster.save", 'rb'))
buckets = pickle.load(open("buckets.save", 'rb'))
while True:
query = input("Search: ")
encoded_query = model.encode(query)
encoded_query = np.expand_dims(encoded_query, axis=0)
bucket = kmeans.predict(encoded_query)
bucket = int(bucket.squeeze())
embeddings = []
for result in buckets[bucket]:
embeddings.append(result["content"])
embeddings = model.encode(embeddings)
neigh = NearestNeighbors(n_neighbors=10)
neigh.fit(embeddings)
indexes = neigh.kneighbors(encoded_query, return_distance=False)
for index in indexes.T:
doc = buckets[bucket][int(index.squeeze())]
print (doc["title"], doc["url"])
print ("")
Matching user query to 10 most relevant pages
In the code above, it shows that I broke the database down into 3 clusters.
However, I did a lot of tinkering with the number of clusters.
If we group the database into too many clusters, searches would be extremely efficient, but there would be a huge drop in result accuracy. The same goes the other way.
I found that, with 3 clusters, the accuracy of the results were really high, however it was still extremely slow to return results (~7 seconds for each search, but the worst was 32 seconds).
Search: how do i compose music
Musical instrument - Wikipedia https://en.wikipedia.org/wiki/Musical_instrument
Elements of music - Wikipedia https://en.wikipedia.org/wiki/Elements_of_music
Music criticism - Wikipedia https://en.wikipedia.org/wiki/Music_criticism
Contemporary classical music - Wikipedia https://en.wikipedia.org/wiki/Contemporary_music
Accompaniment - Wikipedia https://en.wikipedia.org/wiki/Accompaniment
Musical improvisation - Wikipedia https://en.wikipedia.org/wiki/Musical_improvisation
Musique concrète - Wikipedia https://en.wikipedia.org/wiki/Musique_concr%C3%A8te
Programming (music) - Wikipedia https://en.wikipedia.org/wiki/Programming_(music)
Film score - Wikipedia https://en.wikipedia.org/wiki/Film_score
Song - Wikipedia https://en.wikipedia.org/wiki/Song
Harpsichord - Wikipedia https://en.wikipedia.org/wiki/Harpsichord
Music theory - Wikipedia https://en.wikipedia.org/wiki/Music_theory
Music industry - Wikipedia https://en.wikipedia.org/wiki/Music_industry
Definition of music - Wikipedia https://en.wikipedia.org/wiki/Definitions_of_music
Wolfgang Amadeus Mozart - Wikipedia https://en.wikipedia.org/wiki/Wolfgang_Amadeus_Mozart
Invention (musical composition) - Wikipedia https://en.wikipedia.org/wiki/Invention_(musical_composition)
Music - Wikipedia https://en.wikipedia.org/wiki/Music
Music - Wikipedia https://en.wikipedia.org/wiki/Music
Aesthetics of music - Wikipedia https://en.wikipedia.org/wiki/Aesthetics_of_music
Musicology - Wikipedia https://en.wikipedia.org/wiki/Musicology
Searches relating to music took the most time, possibly because the database contained a lot of music pages, and so they were all grouped into one big cluster.
With anything above 6 clusters, I found that results were being returned at a quick speed, however the accuracy was poor. For example I'd search something simple, such as "Liverpool Football", but the engine would fail to return the Liverpool F.C page, despite it being present in the database.
A better solution
With the trade-off between speed and accuracy in the above solution being way too sensitive, I had to find a better solution.
After a bit of research, I came across ANNOY .
ANNOY stands for "Approximate Nearest Neighbours Oh Yeah" and is a small library, provided by Spotify, to search for points in space that are close to a given query point.
Spotify themselves use ANNOY for their user music recommendations!
Approximate Nearest Neighbours?
You may be thinking why would we want an approximate nearest neighbours alogrithm? Why not an exact one?
For KNN to be exact, it has to iterate through each and every datapoint given to it, which is obviously extremely inefficient.
Things can be drastically sped up if a little bit of accuracy is sacrificed, but, in practice, this sacrifice in accuracy does not matter at all. A user would not mind if the second closest datapoint and first closest datapoint are swapped around, since they are both probably good matches to their query.
How ANNOY works
ANNOY works by building loads of binary trees (a forest) from the dataset its given.
To build a tree, it selects two random points in the vector space and divides the space into two subspaces, by the hyperplane equidistant to the two random points.

The process repeats again, in the new subspaces that were just made.
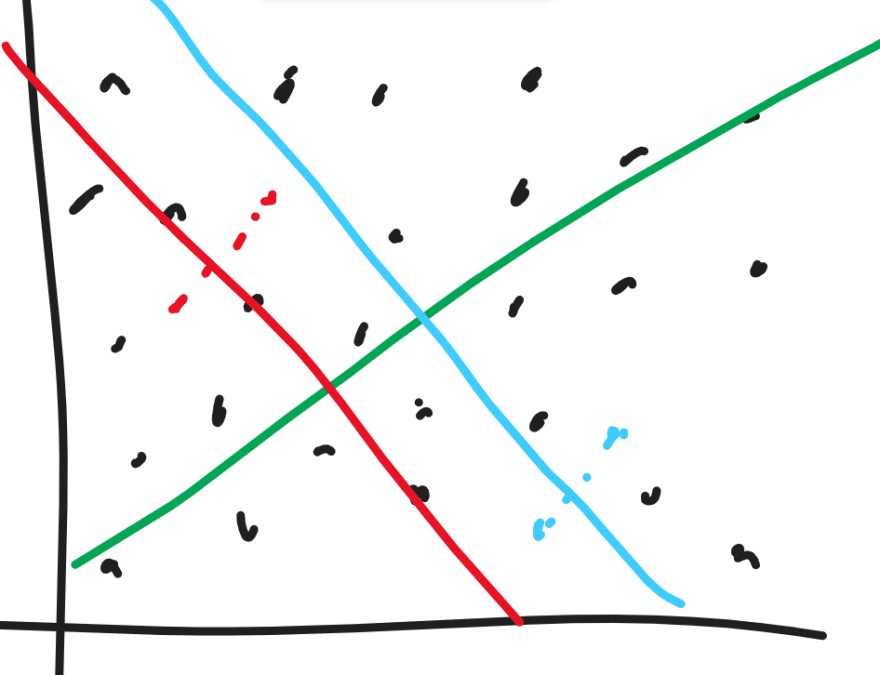
This keeps going until there is a certain n number of points in each subspace.
Points that are near to each other should be in the same subspace, since it is unlikely that there would be a hyperplane to separate them into separate subspaces.
Now that we have all the subspaces, a binary tree can be constructed.
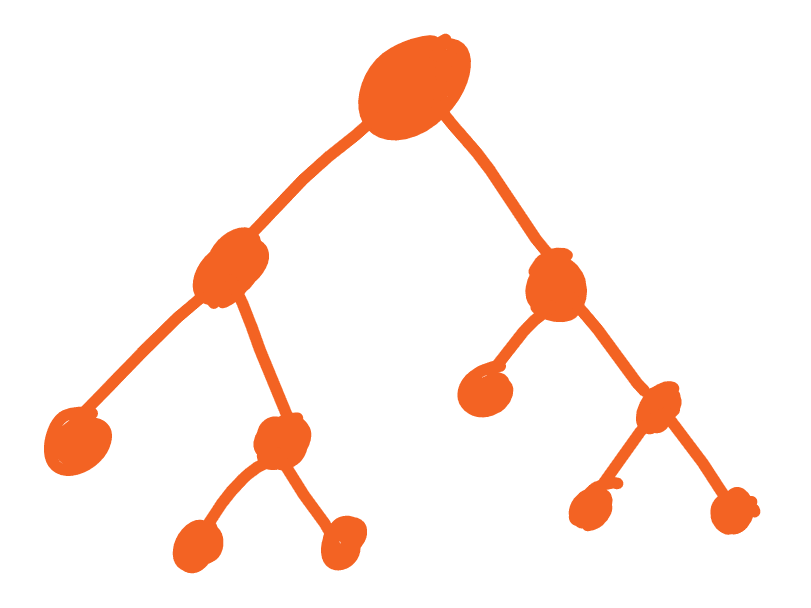
The nodes of the tree represent a hyperplane. So, when given a query vector, we can traverse down the tree, telling us which hyperplanes we should go down to, in order to find some x most relevant points in the vector space.
ANNOY builds many of these trees to build a forest . The number of trees in the forest is specified by the programmer.
When given a query vector, ANNOY uses a priority queue to search this query through the binary trees in its forest. The priority queue allows for the search to focus on trees that are best for the query (aka trees whose hyperplanes are far from the query vector).
After it has finished searching, ANNOY looks at all the common points its trees have found, which would form the query vector's "neighbours".

Now the k nearest neighbours can be ranked and returned

Refactoring Indexing and Search code
It didn't take long to change the code to use ANNOY, thanks to its straightforward API.
from tinydb import TinyDB
from sentence_transformers import SentenceTransformer
from annoy import AnnoyIndex
model = SentenceTransformer('sentence-transformers/stsb-roberta-base-v2')
db = TinyDB("results.json")
descriptions = []
for record in db:
description = record["content"]
descriptions.append(description)
embeddings = model.encode(descriptions)
index = AnnoyIndex(embeddings.shape[-1], "euclidean")
vec_idx = 0
for vec in embeddings:
index.add_item(vec_idx, vec)
vec_idx += 1
index.build(10)
index.save("index.ann") #stores the results of the indexing
Indexing code
from tinydb import TinyDB
from sentence_transformers import SentenceTransformer
from annoy import AnnoyIndex
model = SentenceTransformer('sentence-transformers/stsb-roberta-base-v2')
db = TinyDB("results.json")
index = AnnoyIndex(768, "euclidean")
index.load("index.ann")
while True:
query = input("Search: ")
vec = model.encode(query)
indexes = (index.get_nns_by_vector(vec, 20))
all_db = db.all()
for i in indexes:
print (all_db[i]["title"], all_db[i]["url"])
print ("")
user search code
Now let's see the results...
Search: great composers
Igor Stravinsky - Wikipedia https://en.wikipedia.org/wiki/Igor_Stravinsky
Contemporary classical music - Wikipedia https://en.wikipedia.org/wiki/Contemporary_music
Gustav Mahler - Wikipedia https://en.wikipedia.org/wiki/Gustav_Mahler
Symphony - Wikipedia https://en.wikipedia.org/wiki/Symphony
Art music - Wikipedia https://en.wikipedia.org/wiki/Art_music
Symphony No. 5 (Beethoven) - Wikipedia https://en.wikipedia.org/wiki/Symphony_No._5_(Beethoven)
Wolfgang Amadeus Mozart - Wikipedia https://en.wikipedia.org/wiki/Wolfgang_Amadeus_Mozart
Ludwig van Beethoven - Wikipedia https://en.wikipedia.org/wiki/Ludwig_van_Beethoven
Music of Central Asia - Wikipedia https://en.wikipedia.org/wiki/Central_Asian_music
Big band - Wikipedia https://en.wikipedia.org/wiki/Big_band
Program music - Wikipedia https://en.wikipedia.org/wiki/Program_music
Cello Suites (Bach) - Wikipedia https://en.wikipedia.org/wiki/Bach_cello_suites
Film score - Wikipedia https://en.wikipedia.org/wiki/Film_score
Johann Sebastian Bach - Wikipedia https://en.wikipedia.org/wiki/Johann_Sebastian_Bach
Elements of music - Wikipedia https://en.wikipedia.org/wiki/Elements_of_music
Music of China - Wikipedia https://en.wikipedia.org/wiki/Chinese_classical_music
Organ (music) - Wikipedia https://en.wikipedia.org/wiki/Organ_(music)
Toccata and Fugue in D minor, BWV 565 - Wikipedia https://en.wikipedia.org/wiki/Toccata_and_Fugue_in_D_minor,_BWV_565
Georg Philipp Telemann - Wikipedia https://en.wikipedia.org/wiki/Georg_Philipp_Telemann
Sonata form - Wikipedia https://en.wikipedia.org/wiki/Sonata_form
Search: what are the rules of cricket
No-ball - Wikipedia https://en.wikipedia.org/wiki/No-ball
International cricket - Wikipedia https://en.wikipedia.org/wiki/International_cricket
Toss (cricket) - Wikipedia https://en.wikipedia.org/wiki/Toss_(cricket)
Match referee - Wikipedia https://en.wikipedia.org/wiki/Match_referee
Cricket ball - Wikipedia https://en.wikipedia.org/wiki/Cricket_ball
Board of Control for Cricket in India - Wikipedia https://en.wikipedia.org/wiki/Board_of_Control_for_Cricket_in_India
India national cricket team - Wikipedia https://en.wikipedia.org/wiki/India_national_cricket_team
Caught - Wikipedia https://en.wikipedia.org/wiki/Caught
Substitute (cricket) - Wikipedia https://en.wikipedia.org/wiki/Substitute_(cricket)
International Cricket Council - Wikipedia https://en.wikipedia.org/wiki/International_Cricket_Council
Portal:Cricket - Wikipedia https://en.wikipedia.org/wiki/Portal:Cricket
Delivery (cricket) - Wikipedia https://en.wikipedia.org/wiki/Delivery_(cricket)
Cricketer (disambiguation) - Wikipedia https://en.wikipedia.org/wiki/Cricketer_(disambiguation)
Cricket (disambiguation) - Wikipedia https://en.wikipedia.org/wiki/Cricket_(disambiguation)
Cricket West Indies - Wikipedia https://en.wikipedia.org/wiki/Cricket_West_Indies
Zimbabwe Cricket - Wikipedia https://en.wikipedia.org/wiki/Zimbabwe_Cricket
Bowled - Wikipedia https://en.wikipedia.org/wiki/Bowled
Pakistan Cricket Board - Wikipedia https://en.wikipedia.org/wiki/Pakistan_Cricket_Board
World Cricket League - Wikipedia https://en.wikipedia.org/wiki/World_Cricket_League
West Indies cricket team - Wikipedia https://en.wikipedia.org/wiki/West_Indies_cricket_team
As you can see, the results returned are pretty accurate! It obviously doesn't help that the database I had was pretty small, but this did yield some good results despite it!
On top of that, these results were produced almost instantly, much much quicker than the previous solution.
Conclusion
The only thing I could see that stopped from the search results being better was the size of the database. If I did set out to build a much bigger search engine in the future, I'd look to use databases such as Firebase or MongoDB, and look into how ANNOY could interface with them.
Having said that, I built this project to investigate how deep learning models could be used in document searching tasks and what can be done to efficiently perform the searches and I think I've taken a lot away from this project.
Thank you for reading and I hope you've learnt something from this too!
Теги
#
Ресурс : dev.to

